I tried using GPTHuman AI Review to evaluate my AI-generated content, but I’m not sure if I set it up correctly or if I’m interpreting the results the right way. Can someone explain how GPTHuman AI Review is supposed to work, what I should look for in the output, and how to use the feedback to actually improve content quality and accuracy?
GPTHuman AI Review
I tried GPTHuman after seeing the line about being “the only AI humanizer that bypasses all premium AI detectors.” That line pulled me in, but the results did not match it.
The full writeup with extra screenshots is here if you want context:
https://cleverhumanizer.ai/community/t/gpthuman-ai-review-with-ai-detection-proof/30
So here is what happened when I put it through the usual tests.
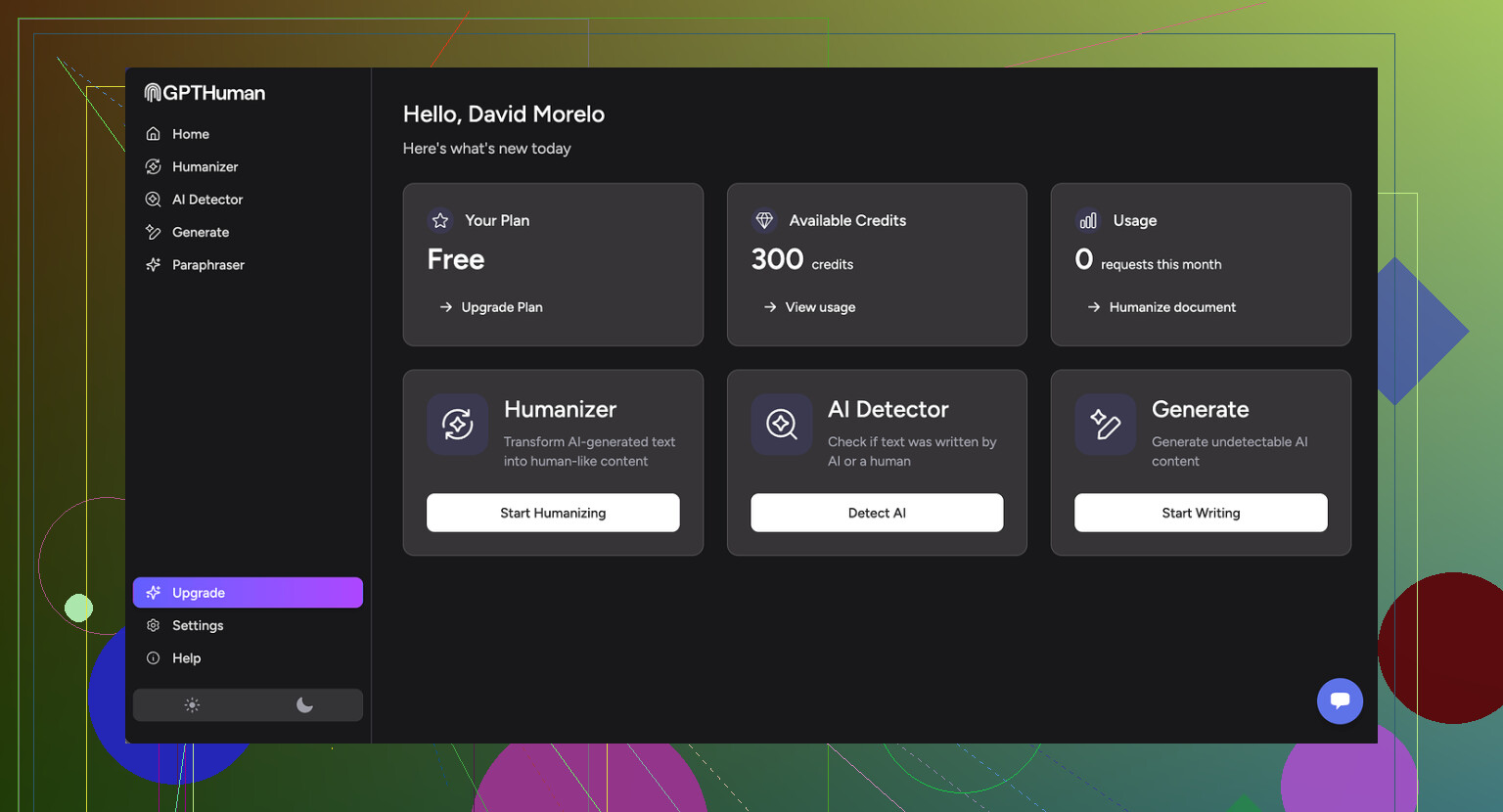
First, I fed three different texts through GPTHuman and then ran those through a couple of the popular detectors:
• GPTZero flagged every single “humanized” output as 100% AI. All three. No borderline scores.
• ZeroGPT passed two samples at 0% AI, but the third one came back around 30% AI probability.
On the GPTHuman side, the internal “human score” looked great. It kept telling me the outputs were highly human. Those numbers did not line up with the external detectors at all, which makes the built-in metric feel more like a comfort stat than something you can rely on.
Text quality was mixed. Paragraphs were structured fine, so in terms of layout it looked like something a person could have written. Once I read it more closely though, problems started piling up:
• Subject and verb did not match in multiple sentences.
• Some sentences trailed off or were missing key parts.
• A few synonym swaps broke the meaning of the sentence.
• Several conclusions at the end of the pieces were almost unreadable.
So you get content that looks normal at a glance but falls apart when you check grammar and clarity.
Now about pricing and limits. This part annoyed me more than the detection scores.
The free tier stopped at around 300 words total processed across all runs. After that, the site blocked me. I ended up using three different Gmail accounts to finish the full set of tests I usually run. That felt like trial mode, not a useful free tier.
Here is how the paid plans looked when I checked:
• Starter plan from $8.25 per month if you pay annually.
• “Unlimited” plan at $26 per month, but each output is still capped at 2,000 words per run.
So unlimited does not mean unlimited length. If you work with long-form pieces, you would have to chop them into chunks and process them separately.
There were also a few policy details you might want to know before you put money into it:
• Purchases are non-refundable. No trial refund safety net.
• Content you submit is used for AI training by default, unless you go in and opt out.
• They state they can use your company name in their marketing unless you ask them not to.
If you work with clients or sensitive drafts, that combination is not ideal.
During the same round of tests, I benchmarked multiple tools side by side. On my runs, Clever AI Humanizer gave stronger detector scores and was easier to work with because it stayed free and did not throw hard usage walls at me.
Full reference link again:
https://cleverhumanizer.ai/community/t/gpthuman-ai-review-with-ai-detection-proof/30
2 Likes
Short version. GPTHuman AI Review is mostly a “rewrite and self-score” tool, not a serious evaluator of AI vs human text.
How it is supposed to work
- You paste AI text.
- It rewrites it to look “more human”.
- It shows its own “human score”.
- You then run that output into other detectors if you care about external results.
The key point. That internal “human score” is only its own model’s guess. It is not tied to GPTZero, ZeroGPT, Originality, etc. So when you see 90%+ “human” inside GPTHuman, it only means “GPTHuman thinks GPTHuman did ok”. It does not mean other detectors will agree.
How to set it up so results make sense
-
Decide your actual goal
• Passing third party detectors
• Better readability and style
• Both -
For detector goals
• Ignore the GPTHuman score.
• Use a fixed workflow. Example:- Generate content with your LLM.
- Human edit a bit first. Change structure, not only synonyms.
- If you still want, run through GPTHuman on lowest “aggressiveness” options so it does not wreck meaning.
- Then test the final text on 2 different detectors and track their percentages.
-
For quality goals
• Read the output out loud.
• Check three things: subject verb agreement, sentence completeness, and logic of each paragraph.
• Fix grammar by hand. GPTHuman tends to break agreement and drop phrases. You saw that. That is normal for this class of tools.
What you are misreading (in my opinion)
You treated the “human score” like a cross-detector truth. It is not.
You also expected a “bypass all premium AI detectors” type result. That line is marketing. Detectors change models and thresholds all the time. No single humanizer stays ahead for long.
Where I slightly disagree with @mikeappsreviewer
I do not think GPTHuman is useless. It can be ok for light paraphrasing if you already know how to manually clean the text after. I would not trust it alone for long form or client work, especially with the 2,000 word cap and the training-by-default policy.
If your core need is better detector scores plus readable output, I would lean toward a tool that optimizes for that directly. Clever Ai Humanizer focuses on detector compatibility and keeps the free access more open, so it is easier to run side by side tests without hitting hard walls. For SEO content or blog posts, that is more practical.
Concrete steps you can try next
- Take one of your AI articles, around 800 to 1,200 words.
- Run version A through GPTHuman with default settings.
- Run version B through Clever Ai Humanizer.
- Send original, A, and B to the same set of detectors.
- Compare three things, not only scores:
• Detector percentages.
• Grammar errors per 100 words.
• How “natural” it feels when you read it out loud.
After two or three tests you will see a pattern. At that point you will stop caring about the internal GPTHuman score and only trust data from external tools and your own manual review.
If all you need is evaluation, skip GPTHuman completely and run your raw AI text straight into detectors plus a grammar checker. The “humanizer” layer only helps if it does not damage meaning or grammar, and with GPTHuman you have to babysit it a lot.
You’re not crazy, GPTHuman is just kind of… confusing by design.
Couple of key points that might clear up what you’re seeing:
-
What GPTHuman is actually doing
It’s primarily a rewrite tool with a self-made “human score,” not a true detector.- You paste AI text.
- It rewrites it using its own model.
- Then it grades its own output using its own internal metric.
That % score is only “GPTHuman thinks this looks human-ish.” It’s not correlated to GPTZero, ZeroGPT, Originality, etc. So if you’re expecting “92% human” inside GPTHuman to translate to “passes real detectors,” it just won’t.
-
Why your detector results look off
You saw GPTZero still calling everything 100% AI after GPTHuman. That actually makes sense:- Most humanizers over-focus on word swaps and sentence shuffling.
- Modern detectors look at deeper patterns: structure, repetitiveness, coherence, burstiness.
GPTHuman is trying to patch the surface, while detectors are checking the bones of the text. So yeah, the mismatch you saw is exactly what I’d expect.
-
Interpreting the “human score”
This is where I slightly disagree with @nachtdromer. I wouldn’t treat that score as useful even for casual work. It’s not calibrated, not transparent, and not comparable across tools.
I’d treat it as:- A vanity stat that might roughly track how much it rewrote the text.
- Not an actual measure of “this will pass detector X or Y” and not a sign of real human quality.
-
The grammar and logic issues you got
What you described- Subject/verb mismatches
- Broken sentences
- Synonyms that alter meaning
- Unreadable conclusions
That usually happens when a tool is tuned harder toward “let’s be different enough to fool detectors” than “let’s be correct.” It tries to break patterns and ends up breaking language.
If you have to manually fix grammar, logic, and flow after every run, the “humanizer” is just adding work instead of reducing it.
-
Setup vs expectations
I don’t think you “set it up wrong.” You just aimed it at the wrong job:- If your goal is evaluation, GPTHuman isn’t the right stage in the pipeline. You should be:
- Generating content
- Editing it yourself
- Sending it to actual detectors directly
- If your goal is paraphrasing to look less AI-ish, GPTHuman is usable but must be followed by manual cleanup and external checks.
- If your goal is evaluation, GPTHuman isn’t the right stage in the pipeline. You should be:
-
Where I differ a bit from @mikeappsreviewer
I agree with their conclusion that GPTHuman oversells the “bypass all premium AI detectors” claim. That’s just marketing.
Where I’m slightly less harsh: it can help break the obvious “ChatGPT voice” if you run it lightly and already know how to spot and fix nonsense. But if you’re hoping for a one-click “undetectable” button, it’s the wrong tool. -
Practical way to think about it
If you need:- Detector-proof text: run your raw content through detectors + a grammar checker. If you still care about tweaking for detectors, a tool like Clever Ai Humanizer is built more around detector compatibility and tends to keep things more readable in longer tests.
- Just better writing: skip GPTHuman, edit by hand or use a regular editing model. Human style comes more from structure, pacing, specificity, and personal detail than random synonym swaps.
-
About pricing and limits
Your frustration with the 300-word “free” cap and 2,000-word “unlimited” cap is valid. That feels more like a paywall strategy than a real free tier. Combine that with:- Non-refundable purchases
- Auto opt-in to training with your content
- Using your brand name in their marketing by default
and it’s hard to justify using it for serious or client-sensitive stuff.
TL;DR:
You didn’t misconfigure anything. GPTHuman is working as intended, just not as advertised. Treat it as a risky paraphraser with a vanity score, not as a reliable evaluator. For actual evaluation, go straight to detectors. For “more human” and still-readable content, something like Clever Ai Humanizer plus your own edits is usually a cleaner, less annoying workflow.
Short version: you didn’t set GPTHuman up wrong; you expected it to behave like a detector or a serious editor, and it just isn’t built for that.
Let me come at this from a slightly different angle than @nachtdromer, @techchizkid and @mikeappsreviewer, without replaying all their steps.
1. Think of GPTHuman as a style filter, not a truth meter
The “human score” is not only detached from external detectors, it is also detached from any clear linguistic standard. There is no evidence it is calibrated on real human corpora or benchmarked to specific detectors. So:
- High score = “GPTHuman thinks its rewrite looks different enough from the input.”
- Low score = “GPTHuman thinks it did not move far from the input.”
That is it. I would not even use that number as a soft proxy for quality. I actually disagree a bit with the idea that it is “ok as a light paraphraser metric.” If a metric is opaque and not validated, I would ignore it completely and just read the text.
2. Where GPTHuman can still be mildly useful
There are two very narrow cases where I can see it helping:
- You have very obviously “LLM-y” text and you want a first-pass shakeup of phrasing before you manually rewrite.
- You are experimenting with patterns detectors hate (overly tidy sentences, low variation, repetitive openings) and you want to see how a different model scrambles them.
Even then, you should:
- Treat the output as a draft that must be copyedited.
- Never trust it unsupervised for anything high stakes or long form.
Once you saw broken subject verb agreement and mangled conclusions, that is enough to classify it as “experimental only.”
3. About detectors and “bypassing”
Modern AI detectors care about:
- Distribution of sentence lengths
- Repetition of rare vs common tokens
- Predictability of next-token choices
- Global structure and coherence patterns
A tool that mainly does synonym swaps and local rewrites will always lag behind. That is why your GPTZero results did not move.
Where I slightly disagree with some of the earlier comments: I would not build an entire workflow around any “humanizer” for bypassing detectors. I would:
- Write with a mix of AI and actual human drafting.
- Inject specific details, small errors, personal asides, real examples.
- Use detectors only as a sanity check, not as the primary goal.
If a text reads naturally to a human and still gets flagged, fighting the detector endlessly is often wasted effort.
4. How Clever Ai Humanizer fits in
If you still want a tool in this category, Clever Ai Humanizer is closer to what people think GPTHuman is:
Pros of Clever Ai Humanizer
- Tuned more directly around detector compatibility rather than vanity scoring.
- Typically keeps grammar more stable than the kind of output you showed from GPTHuman.
- More usable free access, which matters if you want to test multiple variants.
- Better suited for SEO-style content where you care about flow plus lower AI flags.
Cons of Clever Ai Humanizer
- Still not magic. It will not guarantee passes on every detector update.
- You can get subtle meaning drift on technical or legal content, so human review is mandatory.
- For very personal, narrative writing, the results can feel slightly generic if you do not add your own voice after.
- It is yet another layer in the pipeline, which means extra time and one more system handling your text.
I would treat Clever Ai Humanizer as “an optimizer you put near the end of the process” rather than the core engine. Write → lightly edit → optionally humanize → manually proofread → then, if needed, run your detector tests.
5. Practical mental model going forward
- GPTHuman: self-scoring rewriter, fine for curiosity and low stakes tests, poor for reliability.
- Detectors: use at the end, not as the thing you design every sentence around.
- Humanizers like Clever Ai Humanizer: use sparingly and always follow with human editing.
If you anchor your judgment on how the text reads out loud to you and a couple of trusted peers, the internal score in GPTHuman stops mattering almost completely. That is probably the most important shift here.